Now that we have PDF OCR X installed, let's use it to convert a scanned PDF file into text. For the purpose of this tutorial, you can download out sample scanned PDF from here. Notice that this file contains an image of a document. There is no text embedded. If you try to search in the PDF for words or phrases that are clearly in the document, you won't find any matches. Similarly, if you try to copy and paste portions into a text editor, it will fail because there isn't actually any text there. This is what OCR (optical character recognition) is for.
After downloading the scansmpl.pdf file, navigate to your Downloads folder. You should see the file as the most recent download.
Open your PDF OCR X application. You should be able to do this by navigating to your "Applications" directory and double-clicking the PDF OCR X icon.
The next step is to select our scansimpl.pdf file for conversion. We can do this in three ways:
Select "File" > "Select File to Convert...", then select the scansimpl.pdf file from the file open dialog.
Click on the "Select file..." button in the PDF OCR X Window, then select the scansimpl.pdf file from the file open dialog.
Drag the icon for the scansmpl.pdf file onto the PDF OCR X window.
Any of these actions will cause a dialog to appear so that you can select your conversion options.
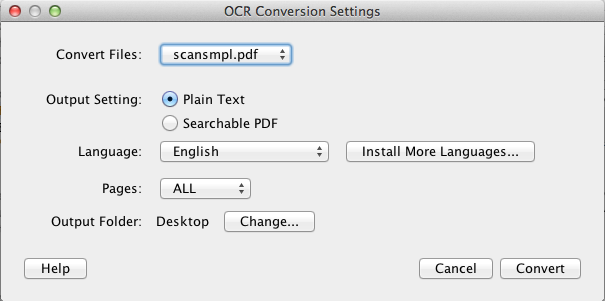
In the OCR Conversion Settings dialog, make sure that "Plain Text" is selected for "Output Setting" and Language is set to "English". Since this is your first time running PDF OCR X, the output folder won't be set yet. Click the "Change..." button next to "Output Folder" to select an output folder where the converted file will be saved. For the purposes of this tutorial, please select "Desktop".
Click the "Convert" button. This should cause a progress indicator to appear in the PDF OCR X window as the OCR process completes. For this single-page file the conversion will only take a few seconds. Larger documents may take more time.
When the conversion is complete, the file will be opened automatically in your default text editor.
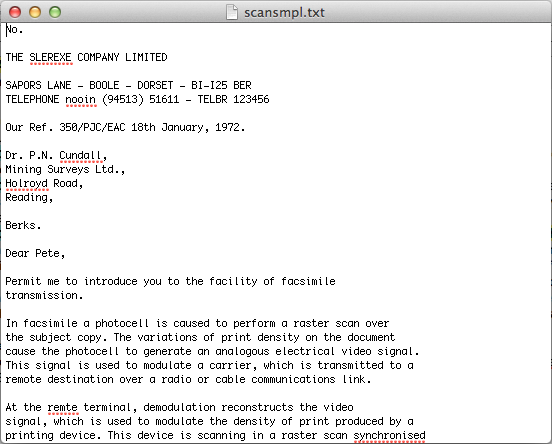
This text can now be edited freely, or pasted into a word processor like Microsoft Word to add formatting and styling.
The first example showed how to convert a scanned PDF file to a plain text file so that you can edit the text. Another useful application for OCR is to convert a scanned PDF (which is not searchable) into a searchable PDF by embedding the text inside the document at the appropriate place. While the PDF would still not be editable, this is useful for document archival purposes. The steps are as follows.
Open your PDF OCR X application. You should be able to do this by navigating to your "Applications" directory and double-clicking the PDF OCR X icon.
The next step is to select our scansimpl.pdf file for conversion. We can do this in three ways:
Select "File" > "Select File to Convert...", then select the scansimpl.pdf file from the file open dialog.
Click on the "Select file..." button in the PDF OCR X Window, then select the scansimpl.pdf file from the file open dialog.
Drag the icon for the scansimpl.pdf file onto the PDF OCR X window.
Any of these actions will cause a dialog to appear so that you can select your conversion options.
In the OCR Conversion Settings dialog, change "Output Setting" to "Searchable PDF" and ensure that Language is set to "English". Since this is your first time running PDF OCR X, the output folder won't be set yet. Click the "Change..." button next to "Output Folder" to select an output folder where the converted file will be saved. For the purposes of this tutorial, please select "Desktop".
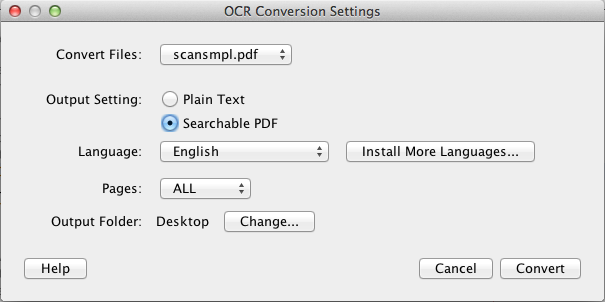
Click the "Convert" button. This should cause a progress indicator to appear in the PDF OCR X window as the OCR process completes. For this single-page file the conversion will only take a few seconds. Larger documents may take more time.
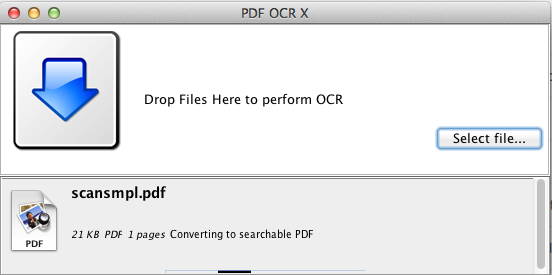
When the conversion is complete, the file will be opened automatically in your default PDF viewer.

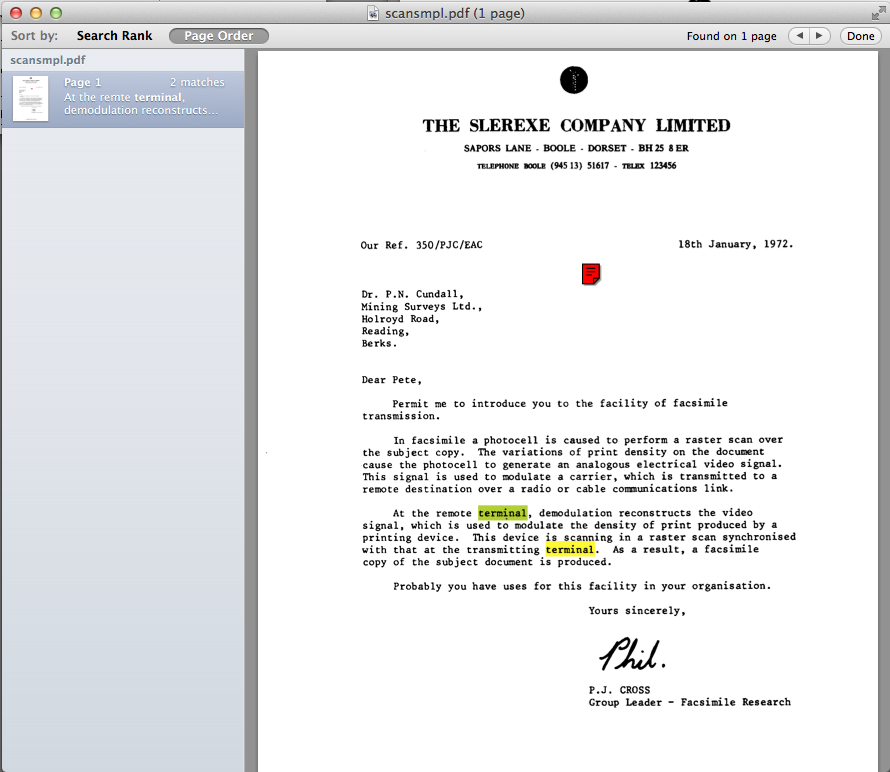
Now, just to verify that it worked, and the PDF is now searchable. try performing a search in the PDF file. Difference PDF viewers may have different ways to search, but typically you would press COMMAND (⌘)-F, and on Windows you would typically press Control-F, but there is usually an alternative approach using the application menus. The in the following screenshot I'm searching for the word "terminal". You can see that the PDF viewer highlights the "terminal" text correctly.